Agents Are Not APIs: Why They Need Control Planes
Agents are not APIs.
That sounds obvious, but most teams still treat them like one:
call → response → done.
That mental model breaks the moment you ship.
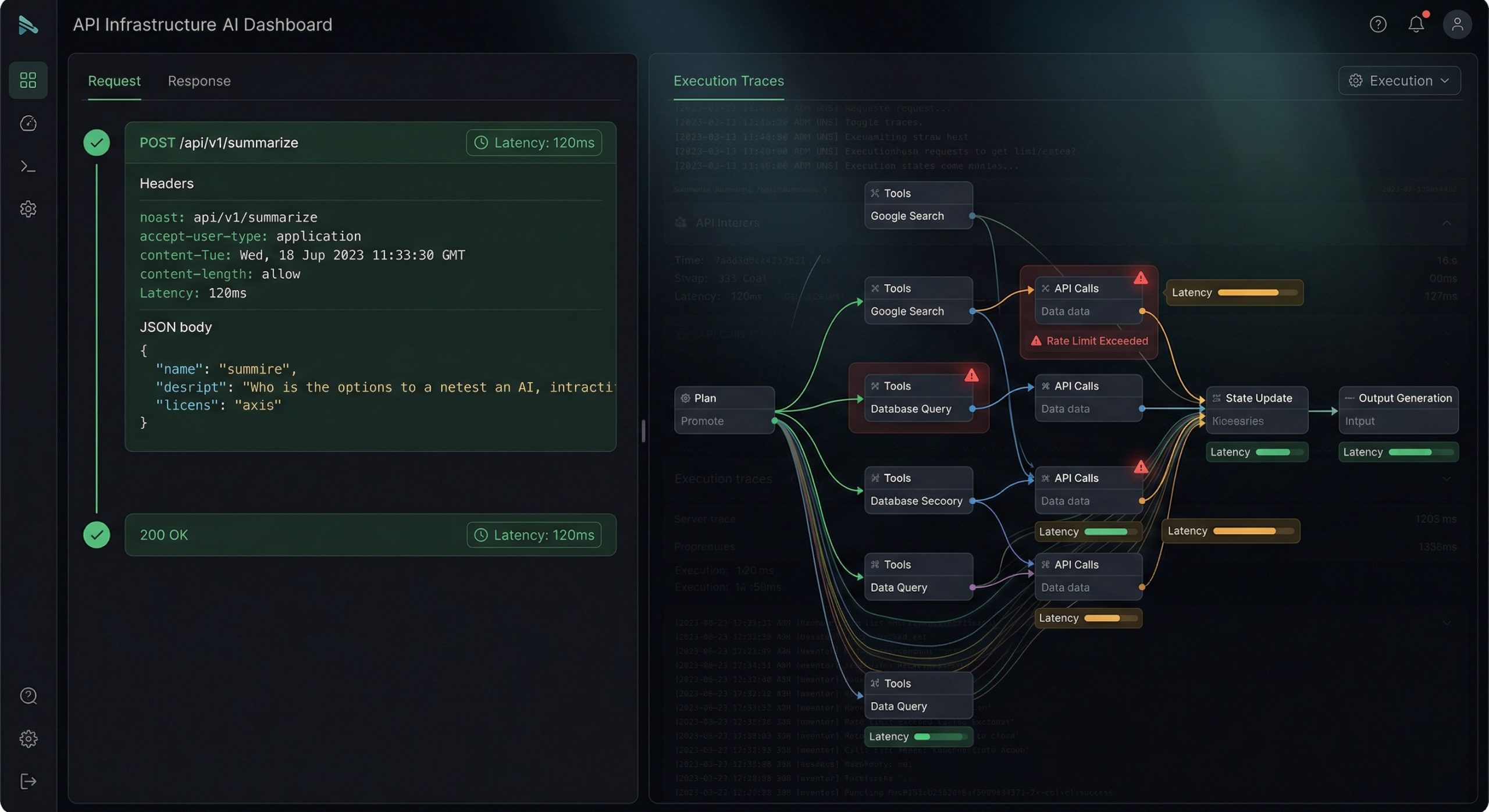
Agents are not APIs—they are multi-step systems:
plan → select tools → call APIs → update state → produce outputEach step introduces uncertainty, branching, and failure modes.
If you treat agents like APIs, you get:
- silent failures
- unpredictable cost
- no reproducibility
- no way to debug
If you treat them like distributed systems, things start to make sense.
Why Agents Are not APIs (The Core Misunderstanding)
APIs are deterministic interfaces.
Agents are probabilistic workflows.
| Property | APIs | Agents |
|---|---|---|
| Execution model | Single request/response | Multi-step workflow |
| Determinism | High | Low |
| Failure visibility | Explicit errors | Silent degradation |
| Debugging | Logs + stack traces | Requires full execution trace |
| Cost profile | Predictable | Variable (tokens, retries, tools) |
| State | Stateless (mostly) | Stateful across steps |
This difference is not cosmetic.
It fundamentally changes how you need to operate them.
Why Treating Agents like APIs Breaks in Production
When an API fails, it tells you.
When an agent fails, it often looks like it worked.
Examples:
- The agent calls the right tool… with the wrong parameters
- The answer is correct… but based on irrelevant retrieval
- The task completes… but costs 10× more
- A tool fails… but the agent continues anyway
Nothing crashes. No alerts fire.
But your system is now unreliable.
Why Agents Need a Control Plane (Not API Thinking)
Infrastructure engineers already solved this problem.
Not for agents but for systems that look very similar.
Agents need a control plane.
A control plane is what turns:
- chaos → orchestration
- best-effort → reliability
- black box → observable system
Mapping Agents to Systems Engineers Already Understand
1. Kubernetes → Orchestrating Execution
Kubernetes doesn’t care what your app does.
It ensures:
- scheduling
- retries
- scaling
- health checks
Agents need the same thing.
| Kubernetes Concept | Agent Equivalent |
|---|---|
| Pod | Agent run / task execution |
| Scheduler | Planner / task router |
| Health checks | Step validation / guardrails |
| Restart policy | Retry / fallback logic |
| Resource limits | Token / cost budgets |

Without this layer, you’re manually orchestrating:
- retries
- fallback logic
- execution flow
That doesn’t scale.
2. CI/CD → Defining and Enforcing Correctness
CI/CD exists because:
“It works on my machine” is not good enough.
Agents have the same problem.
| CI/CD Concept | Agent Equivalent |
|---|---|
| Unit tests | Tool-level evals |
| Integration tests | Scenario simulations |
| Build pipeline | Prompt + tool configuration |
| Deployment gates | Pass/fail eval thresholds |
| Regression detection | Shadow evals / replay |
If you don’t gate agents:
- prompt tweaks introduce regressions
- tool changes silently break workflows
- performance drifts over time
You’re shipping blind.
3. Observability Stacks → Seeing What Actually Happened
Logs are not enough.
Metrics are not enough.
Agents require traces.
| Observability Layer | Agent Requirement |
|---|---|
| Logs | Raw outputs |
| Metrics | Latency, cost, success rate |
| Traces | Full step-by-step execution path |
| Alerts | SLA violations (cost, latency, safety) |
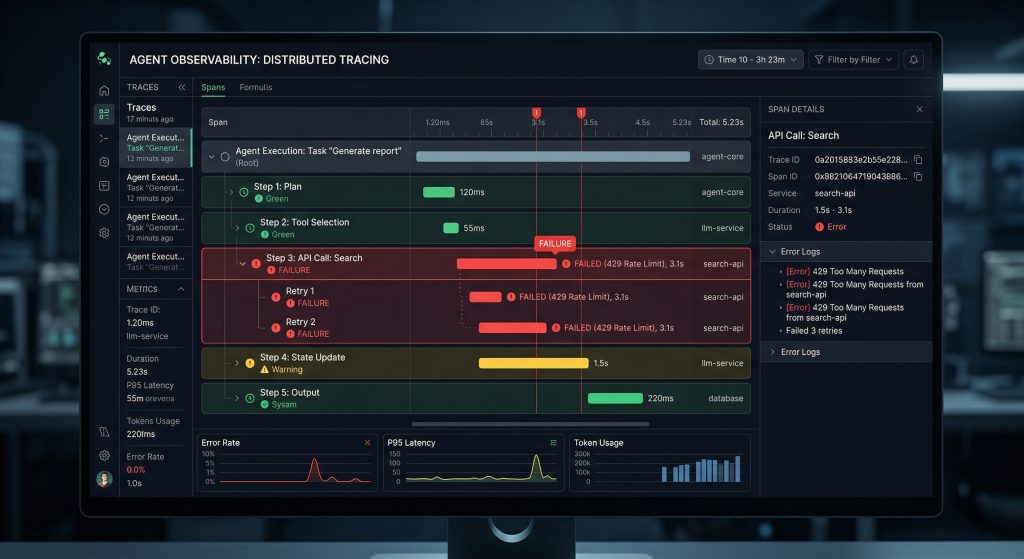
Without traces, you cannot answer:
- Why did the agent choose this tool?
- Where did the cost spike?
- What caused the wrong answer?
You only see the final output.
And that’s the problem.
What a Real Agent Control Plane Looks Like
A proper control plane combines all three layers:
1) Execution Control
- task orchestration
- retries + fallbacks
- budget enforcement
2) Evaluation Layer
- task-level success criteria
- scenario simulations
- regression detection
3) Observability Layer
- full execution traces
- step-level metrics
- failure attribution
The Mental Model Shift
Stop thinking:
“This is an API I can call.”
Start thinking:
“This is a distributed system I need to operate.”
| Old Model | New Model |
|---|---|
| Endpoint | Workflow |
| Response | Execution trace |
| Success | Meets SLA (cost, latency, quality) |
| Debugging | Inspect output |
| Debugging (correct) | Inspect trajectory |
The Cost of Getting This Wrong
If you don’t build a control plane:
- You won’t detect failures until users complain
- You won’t know what broke
- You won’t be able to reproduce issues
- You won’t trust your own system
And eventually:
You’ll stop shipping agent features.
Not because they don’t work.
But because you can’t operate them reliably.
The Bottom Line
Agents are not APIs.
They are:
- non-deterministic
- multi-step
- stateful
- failure-prone systems
And systems like that always require:
- orchestration
- evaluation
- observability
In other words:
A control plane.
Final Thought
Every serious infra evolution followed the same path:
- VMs → Kubernetes
- Code → CI/CD
- Services → Observability
Agents are next.
The teams that win won’t have better prompts.
They’ll have better control planes.
Want this in your stack?
We help Series B+ companies optimize their LLM infrastructure for cost and latency.
Audit
Full analysis of your current prompt engineering and infrastructure.
Sprint
2-week intensive implementation of semantic caching and eval pipelines.
Retainer
Ongoing access to our engineering team for architectural reviews.