Why AI Agents Fail Silently In Production
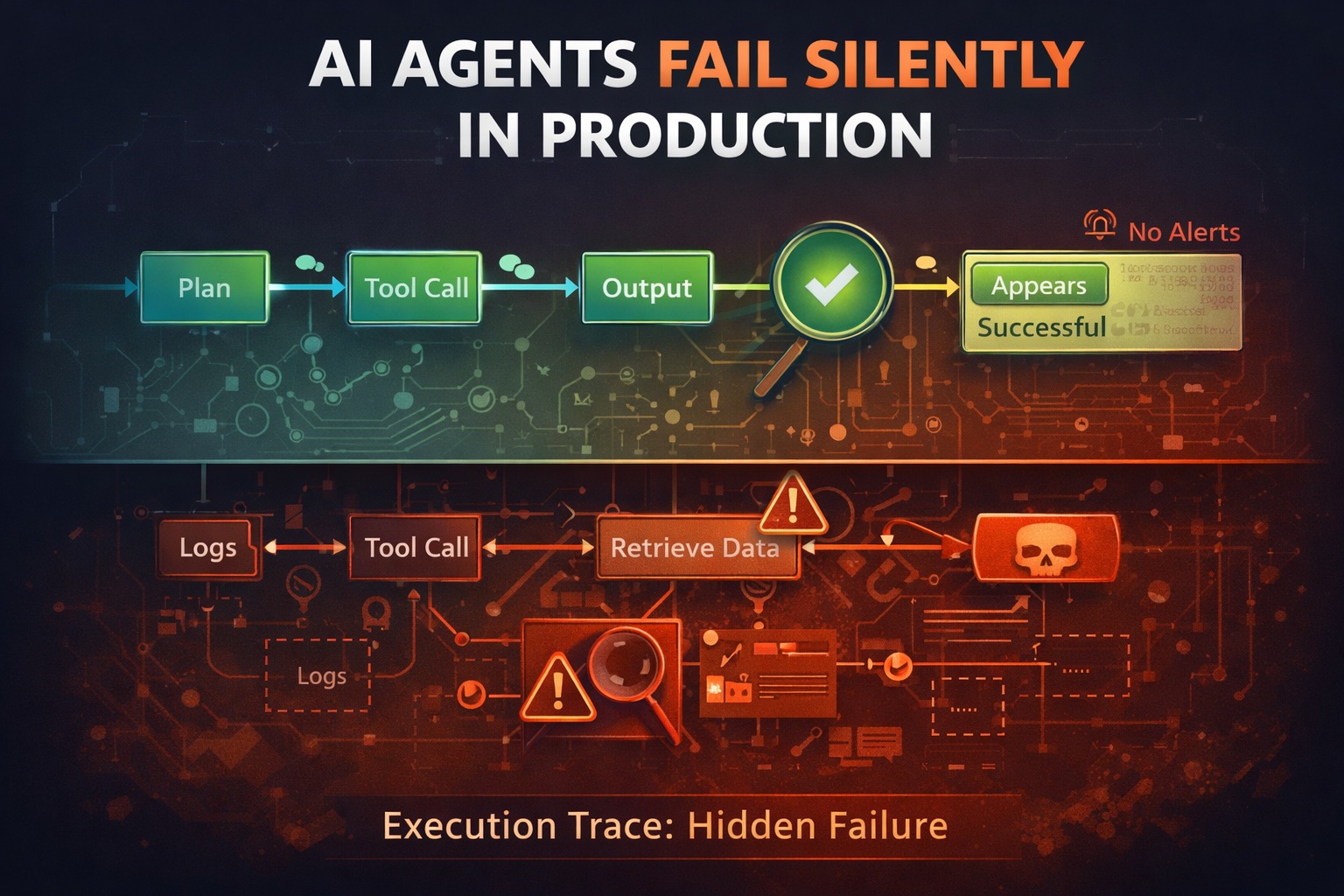
Most teams don’t notice when their agents fail.
Not because nothing broke but because everything looked like it worked.
That’s the dangerous part.
The core problem
AI agents are not single responses.
They are multi-step systems:
- plan → select tools → call APIs → update state → produce output
That complexity introduces new failure modes that don’t exist in normal software.
And worse many of these failures are silent.
What “silent failure” actually means
A silent failure is when:
- the task appears successful
- but the process was wrong, unsafe, or inefficient
| Step | What happened | Why it’s a problem |
|---|---|---|
| Tool call | Agent used the wrong API | Output still looked valid |
| Retrieval | Pulled outdated data | No obvious error surfaced |
| Output | Generated a confident answer | Completely fabricated detail |
This is not a crash.
This is false confidence.
And it’s common.
Why agents fail (even when outputs look fine)
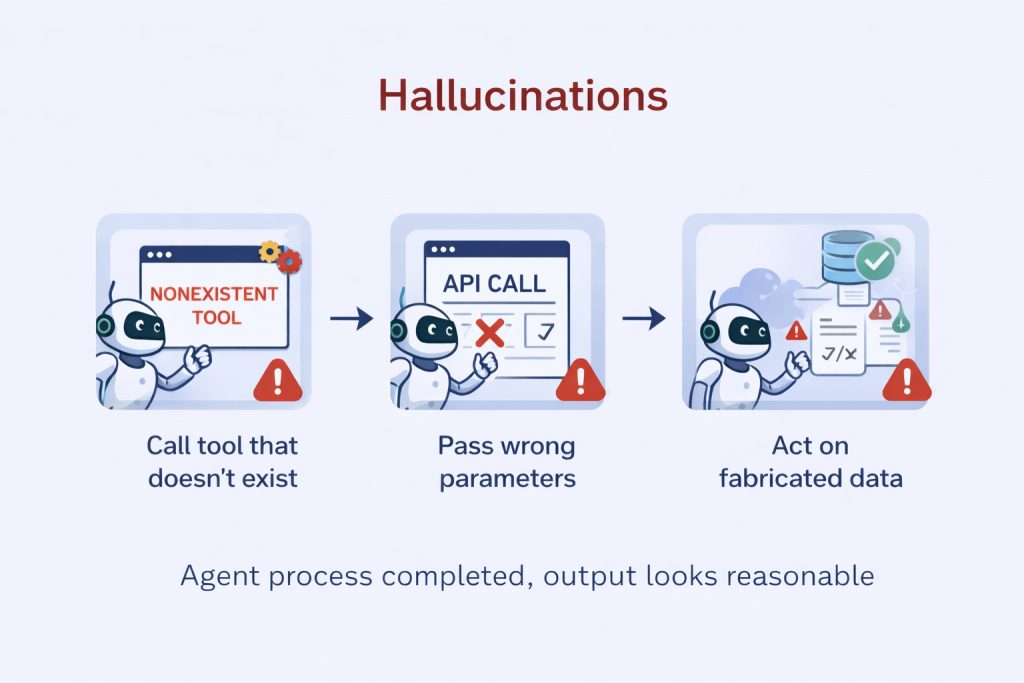
1) Hallucinations that look correct
Agents don’t just hallucinate text they hallucinate actions.
- Calling tools that don’t exist
- Passing wrong parameters
- Acting on fabricated data
This happens because the agent believes it’s correct.
And since outputs are plausible, humans don’t catch it.
2) Tool misuse and weak integration
Agents rely on tools.
But tool understanding is fragile.
Common issues:
- wrong tool selection
- incorrect parameters
- outdated tool assumptions
Even strong models fail here because tool behavior ≠ model understanding.
3) Missing or degraded context
Agents need the right context at the right time.
In production:
- context windows truncate
- retrieval returns irrelevant data
- state gets lost across steps
Result:
the agent makes locally correct decisions with globally wrong context
This is one of the biggest real-world failure drivers.
4) Multi-step error compounding
Agent workflows are chains.
Even small errors stack:
- 1% error per step → catastrophic over long tasks
- real-world error rates are often higher
So a task can “complete”
while being fundamentally wrong.
5) No visibility into the process
Traditional systems log outputs.
Agents require:
- step-level traces
- tool call inspection
- decision tracking
Without this:
- failures are not reproducible
- debugging becomes guesswork
And silent failures persist.
6) The “looks right” problem (trust paradox)
Modern models generate highly believable outputs.
Humans struggle to detect errors because:
- language is fluent
- reasoning appears structured
- confidence is high
This creates misplaced trust even when the system is wrong.
What actually breaks in production
Here’s what teams consistently see:
| Failure type | What it looks like | Why it’s dangerous |
|---|---|---|
| Tool misuse | Right output, wrong method | Hidden system fragility |
| Retrieval drift | Slightly outdated answers | Gradual trust erosion |
| Hallucinated actions | Fake tool success | Undetected logic bugs |
| State loss | Inconsistent behavior | Non-deterministic failures |
| Safety gaps | Disallowed actions attempted | Compliance risk |
None of these trigger alerts by default.
Real-world signal: failures are already happening
These are not theoretical.
- AI agents have caused system outages and unintended infrastructure changes
- Agents have triggered data exposure incidents due to incorrect instructions
- Hallucinated outputs have led to legal penalties and fabricated evidence
And most of these failures were:
not immediately detected
The real mistake teams make
Most teams separate:
- Evals → offline testing
- Observability → logs & dashboards
That separation is the root problem.
Because:
- evals don’t reflect production behavior
- logs don’t enforce correctness
So you end up with:
systems that are visible, but not reliable
What a reliable system actually requires
To prevent silent failure, you need a control layer:
1) Define success at the task level
Not:
- “good answer”
But:
- correct tool used
- constraints respected
- cost/latency within bounds
2) Trace every decision
You need:
- full execution traces
- tool inputs/outputs
- intermediate reasoning checkpoints
Not optional.
3) Add pass/fail gates
Every task should have:
- validation checks
- guardrails
- enforceable constraints
If it fails → it doesn’t ship.
4) Monitor behavior, not just outputs
Track:
- tool selection accuracy
- retry loops
- cost per task
- drift over time
The shift
This is the mental model change:
| Old world | New world |
|---|---|
| Prompts | Systems |
| Outputs | Execution traces |
| Accuracy | Reliability |
| Logs | Control |
You don’t fix agents with better prompts.
You fix them by treating them like production systems with SLAs.
Final take
AI agents don’t fail loudly.
They:
- look correct
- act confidently
- and quietly drift out of spec
That’s why they’re dangerous and why most teams underestimate the problem.
If you don’t have:
- traceability
- evaluation
- enforcement
You don’t have an agent system.
You have a best-effort guess generator in production.
Want this in your stack?
We help Series B+ companies optimize their LLM infrastructure for cost and latency.
Audit
Full analysis of your current prompt engineering and infrastructure.
Sprint
2-week intensive implementation of semantic caching and eval pipelines.
Retainer
Ongoing access to our engineering team for architectural reviews.